
Version Control
Version Control is a system that records changes to a file or files over time so that you can recall specific version later.
Why do we need version control system?
VCS is an invaluable tool with many benefits to a collaborative software team workflow. Any software project that has more than one developer maintaining source code files should absolutely use a VCS. Additionally, sole-maintainer projects will also greatly benefit from utilizing a VCS. There is arguably no valid reason to forgo the use of a VCS in any modern software development project.


In this approach, all the changes in the files are tracked under the centralized server. The centralized server includes all the information of versioned files, and list of clients that check out files from that central place.
Example: Tortoise SVN
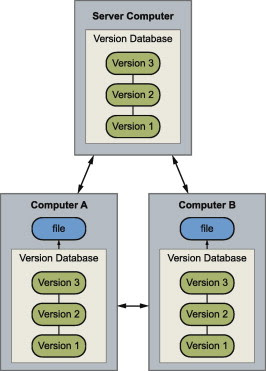
Example: Git
Git is defined as a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
Difference between Git & GitHub

The Three states

Figure 1-6. Working directory, staging area, and Git directory.
Learn more: https://www.atlassian.com/git/tutorials/comparing-workflows

Version Control System
Version Control Systems are process management systems which maintain changes recorded in a file or set of files over period of time. Each change is maintained as a version. Users can track specific versions later. Version control systems are also called as revision control systems. Revision control systems work as independent standalone applications. Applications like spreadsheets and word processors have control mechanisms. The unique features of version control system/ revision control system are as follows:
Up to date history is available for the document and file types.
It does not require any other repository systems.
The repositories can be cloned as per the need and availability. This is extremely helpful in case of failure and accidental deletions.
VCS includes tag system which helps in differentiating between alpha, beta or various release versions for different documents.
It does not require any other repository systems.
The repositories can be cloned as per the need and availability. This is extremely helpful in case of failure and accidental deletions.
VCS includes tag system which helps in differentiating between alpha, beta or various release versions for different documents.
For example, changes made in code base among developers include version control system for tracking changes with specific lines.
The various types of the version control systems are:
1. Local Version Control System
2. Centralized Version Control System
3. Distributed Version Control System
1. Local Version Control System
2. Centralized Version Control System
3. Distributed Version Control System
1.Local Version Control System

Local version control system maintains track of files within the local system. This approach is very common and simple. This type is also error prone which means the chances of accidentally writing to the wrong file is higher.
2.Centralized Version Control Systems

Example: Tortoise SVN
3. Distributed Version Control Systems
Distributed version control systems come into picture to overcome the drawback of centralized version control system. The clients completely clone the repository including its full history. If any server dies, any of the client repositories can be copied on to the server which help restore the server.
Every clone is considered as a full backup of all the data.
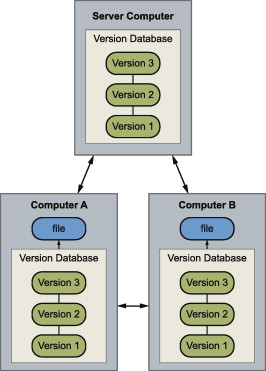
Example: Git
Git is defined as a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
Difference between Git & GitHub
If you have a project under Git, you have access to
all those functionalities like rollback to another version.
But if you want to have an online backup, you need to
keep your project on a accessible server (like Dropbox
website). That way, you can send your work to the server,
clean your computer, and still be able to download a copy
of your work and continue from where you left.
But setting up a (Git) server can be a lot of work. And some of us don’t have the possibility of taking care of a personal server. Well, GitHub can be seen as a Git server as a service. You register, and you can configure your project to be hosted on GitHub (free and paid plans available of course).all those functionalities like rollback to another version.
But if you want to have an online backup, you need to
keep your project on a accessible server (like Dropbox
website). That way, you can send your work to the server,
clean your computer, and still be able to download a copy
of your work and continue from where you left.

Git Commands
| Git task | Notes | Git commands |
|---|---|---|
| Tell Git who you are | Configure the author name and email address to be used with your commits.
Note that Git strips some characters (for example trailing periods) from
user.name. | git config --global user.name "Sam Smith"git config --global user.email sam@example.com |
| Create a new local repository | git init
| |
| Check out a repository | Create a working copy of a local repository: | git clone /path/to/repository
|
| For a remote server, use: | git clone username@host:/path/to/repository
| |
| Add files | Add one or more files to staging (index): | git add <filename>
git add *
|
| Commit | Commit changes to head (but not yet to the remote repository): | git commit -m "Commit message"
|
Commit any files you've added with git add, and also commit any files you've changed since then: | git commit -a
| |
| Push | Send changes to the master branch of your remote repository: | git push origin master
|
| Status | List the files you've changed and those you still need to add or commit: | git status
|
| Connect to a remote repository | If you haven't connected your local repository to a remote server, add the server to be able to push to it: | git remote add origin <server> |
| List all currently configured remote repositories: | git remote -v | |
| Branches | Create a new branch and switch to it: | git checkout -b <branchname>
|
| Switch from one branch to another: | git checkout <branchname>
| |
| List all the branches in your repo, and also tell you what branch you're currently in: | git branch
| |
| Delete the feature branch: | git branch -d <branchname>
| |
| Push the branch to your remote repository, so others can use it: | git push origin <branchname>
| |
| Push all branches to your remote repository: | git push --all origin
| |
| Delete a branch on your remote repository: | git push origin :<branchname>
| |
| Update from the remote repository | Fetch and merge changes on the remote server to your working directory: | git pull |
| To merge a different branch into your active branch: | git merge <branchname>
| |
| View all the merge conflicts:
View the conflicts against the base file:
Preview changes, before merging:
| git diffgit diff --base <filename>git diff <sourcebranch> <targetbranch>
| |
| After you have manually resolved any conflicts, you mark the changed file: | git add <filename>
| |
| Tags | You can use tagging to mark a significant changeset, such as a release: | git tag 1.0.0 <commitID>
|
| CommitId is the leading characters of the changeset ID, up to 10, but must be unique. Get the ID using: | git log
| |
| Push all tags to remote repository: | git push --tags origin
| |
| Undo local changes | If you mess up, you can replace the changes in your working tree with the last content in head:
Changes already added to the index, as well as new files, will be kept.
| git checkout -- <filename>
|
| Instead, to drop all your local changes and commits, fetch the latest history from the server and point your local master branch at it, do this: | git fetch origin
git reset --hard origin/master
| |
| Search | Search the working directory for foo(): | git grep "foo()" |
Git has three main states that your files can reside in: committed, modified, and staged. Committed means that the data is safely stored in your local database. Modified means that you have changed the file but have not committed it to your database yet. Staged means that you have marked a modified file in its current version to go into your next commit snapshot.
This leads us to the three main sections of a Git project: the Git directory, the working directory, and the staging area.

The Git directory is where Git stores the metadata and object database for your project. This is the most important part of Git, and it is what is copied when you clone a repository from another computer.
The working directory is a single checkout of one version of the project. These files are pulled out of the compressed database in the Git directory and placed on disk for you to use or modify.
The staging area is a simple file, generally contained in your Git directory, that stores information about what will go into your next commit. It’s sometimes referred to as the index, but it’s becoming standard to refer to it as the staging area.
The basic Git workflow goes something like this:
- You modify files in your working directory.
- You stage the files, adding snapshots of them to your staging area.
- You do a commit, which takes the files as they are in the staging area and stores that snapshot permanently to your Git directory.
If a particular version of a file is in the Git directory, it’s considered committed. If it’s modified but has been added to the staging area, it is staged. And if it was changed since it was checked out but has not been staged, it is modified. In Chapter 2, you’ll learn more about these states and how you can either take advantage of them or skip the staged part entirely.
Learn more: https://www.atlassian.com/git/tutorials/comparing-workflows
Major benefits of using a CDN
Implement a CDN affects everything, from your internal architecture to the cost of your IT staff, performance management and more. True power of a content delivery network is yet to be revealed in future decades, as it soars by 20% each year, but so far, the major advantages of using one are:
- significantly reduced page load time of your website
- increased revenue by 1% for every 100 ms of improvement to your page load time
- retaining more customers (they are more satisfied)
- more manageable traffic
- maximum availability of your product
- more secure network
- no geographical barriers
- easy delivery of video, audio rich content
- build more interactive website at no cost of losing visitors due to latencies
- reaching mobile customers with ease
- branching out to new markets, regions
- easy management of traffic peaks
- more scalability to your business, you can grow it as much as you want to
- less or now downtimes
- setting your own criteria to enable the best possible performance for your website
Sometimes, using more than one CDN provider is advised because CDN providers perform differently in different geographical regions, and not all CDN providers are reliable as others. This is known as multiple content delivery network or multiple CDN.
CDN Hosting vs Web Hosting

- Web Hosting is used to host your website on a server and let users access it over the internet. A content delivery network is about speeding up the access/delivery of your website’s assets to those users.
- Traditional web hosting would deliver 100% of your content to the user. If they are located across the world, the user still must wait for the data to be retrieved from where your web server is located. A CDN takes a majority of your static and dynamic content and serves it from across the globe, decreasing download times. Most times, the closer the CDN server is to the web visitor, the faster assets will load for them.
- Web Hosting normally refers to one server. A content delivery network refers to a global network of edge servers which distributes your content from a multi-host environment.
Content Delivery Network Market Growing at 26% CAGR to 2020 MarketReportsHub
Free CDNs




Commercial CDNs

References
https://bitbucket.org/product/version-control-software?_ga=2.69514832.1596276106.1550568066-1848139582.1549521913
https://blog.eduonix.com/software-development/learn-three-types-version-control-systems/
https://pedrorijo.com/blog/git-init/
https://git-scm.com/book/en/v1/Getting-Started-Git-Basics
https://www.globaldots.com/advantages-of-content-delivery-network/
https://www.wpexplorer.com/free-cdn-services-for-wordpress/
https://documentation.commvault.com/commvault/v11_adminconsole/article?p=86630.htm
https://www.geeksforgeeks.org/computer-network-types-server-virtualization/
https://www.quora.com/What-are-the-differences-between-an-emulator-and-a-virtual-machine





System Requirements for Virtualization
Review the following requirements for the Virtual Server Protection (VSP) package.
General Package Requirements
The computer on which you plan to install the package must satisfy the following system requirements:
Operating Systems
|
|
Hard Drive
|
500 GB recommended.
Depending upon the number of virtual machines that you are planning to backup, ensure that the backup server computer has sufficient free space to store all virtual machine data.
|
Memory
|
16 GB RAM minimum required
|
Processor
|
All Windows-compatible processors supported
|
IIS
|
IIS must be enabled on the backup server.
|
Supported Web Browsers for the Command Center
You can run the Command Center on the following browsers:
- Apple Safari version 8.0 and later
- Google Chrome v40 and later
- Microsoft Edge
- Microsoft Internet Explorer (IE) v10 or later
- Mozilla Firefox v47.0 or later
Database Engine
Microsoft SQL Server 2014 Express edition is automatically installed during the installation of the package.
The maximum database size for Microsoft SQL Server 2014 Express edition is 10 gigabytes. If your Express edition database approaches the 10 gigabyte limit, a critical event will appear in the dashboard. To increase the size of the database, you can upgrade to Microsoft SQL Server 2014 Standard edition.
Types of Server Virtualization
Server Virtualization is the partitioning of a physical server into number of small virtual servers, each running its own operating system. These operating systems are known as guest operating systems. These are running on another operating system known as host operating system. Each guest running in this manner is unaware of any other guests running on the same host. Different virtualization techniques are employed to achieve this transparency.
Types of Server virtualization :
- HypervisorA Hypervisor or VMM(virtual machine monitor) is a layer that exits between the operating system and hardware. It provides the necessary services and features for the smooth running of multiple operating systems.It identifies traps, responds to privileged CPU instructions and handles queuing, dispatching and returning the hardware requests. A host operating system also runs on top of the hypervisor to administer and manage the virtual machines.
- Para Virtualization It is based on Hypervisor. Much of the emulation and trapping overhead in software implemented virtualisation is handled in this model. The guest operating system is modified and recompiled before installation into the virtual machine.
Due to the modification in the Guest operating system, performance is enhanced as the modified guest operating system communicates directly with the hypervisor and emulation overhead is removed.
Example : Xen primarily uses Para virtualisation, where a customised Linux environment is used to supportb the administrative environment known as domain 0. Advantages:
Advantages:- Easier
- Enhanced Performance
- No emulation overhead
Limitations:- Requires modification to guest operating system
- Full Virtualization It is very much similar to Para virtualisation. It can emulate the underlying hardware when necessary. The hypervisor traps the machine operations used by the operating system to perform I/O or modify the system status. After trapping, these operations are emulated in software and the status codes are returned very much consistent with what the real hardware would deliver. This is why unmodified operating system is able to run on top of the hypervisor.
Example : VMWare ESX server uses this method. A customised Linux version known as Service Console is used as the administrative operating system. It is not as fast as Para virtualisation. Advantages:
Advantages:- No modification to Guest operating system required.
Limitations:- Complex
- Slower due to emulation
- Installation of new device driver difficult.
- Hardware Assisted Virtualization It is similar to Full Virtualisation and Para virtualisation in terms of operation except that it requires hardware support. Much of the hypervisor overhead due to trapping and emulating I/O operations and status instructions executed within a guest OS is dealt by relying on the hardware extensions of the x86 architecture.Unmodified OS can be run as the hardware support for virtualisation would be used to handle hardware access requests, privileged and protected operations and to communicate with the virtual machine.
Examples : AMD – V Pacifica and Intel VT Vanderpool provides hardware support for virtualisation.Advantages:- No modification to guest operating system required.
- Very less hypervisor overhead
Limitations:- Hardware support Required
- Kernel level Virtualization Instead of using a hypervisor, it runs a separate version of the Linux kernel and sees the associated virtual machine as a user – space process on the physical host. This makes it easy to run multiple virtual machines on a single host. A device driver is used for communication between the main Linux kernel and the virtual machine.
Processor support is required for virtualisation( Intel VT or AMD – v). A slightly modified QEMU process is used as the display and execution containers for the virtual machines. In many ways, kernel level virtualization is a specialised form of server virtualization.Examples: User – Mode Linux( UML ) and Kernel Virtual Machine( KVM ) Advantages:
Advantages:- No special administrative software required.
- Very less overhead
Limitations:- Hardware Support Required
- System Level or OS Virtualization Runs multiple but logically distinct environments on a single instance of operating system kernel. Also called shared kernel approach as all virtual machines share a common kernel of host operating system. Based on change root concept “chroot”.
chroot starts during boot up. The kernel uses root filesystems to load drivers and perform other early stage system initialisation tasks. It then switches to another root filesystem using chroot command to mount an on -disk file system as its final root filesystem, and continue system initialization and configuration within that file system.
The chroot mechanism of system level virtualisation is an extension of this concept. It enables the system to start virtual servers with their own set of processes which execute relative to their own filesystem root directories.
The main difference between system level and server virtualisation is whether different operating systems can be run on different virtual systems. If all virtual servers must share the same copy of operating system it is system level virtualisation and if different servers can have different operating systems ( including different versions of a single operating system) it is server virtualisation.Examples: FreeVPS, Linux Vserver and OpenVZ are some examples. Advantages:
Advantages:- Significantly light weight than complete machines(including a kernel)
- Can host many more virtual servers
- Enhanced Security and isolation
Limitations: - Kernel or driver problem can take down all virtual servers. How does the emulation is different from VMs? Emulator emulates the hardware completely in software. Therefore you can play Amiga or SNES games on an emulator in PC although these consoles had completely different hardware and processor. It’s not just for legacy gaming - you can run an operating system on an emulator on an emulated hardware that no longer exists (or is difficult to obtain). Another typical use-case for emulator can be cross-platform compilation of code (on different platforms x86, MIPS, 32 bit ARMv7, ARMv8, PowerPC, SPARC, ETRAX CRIS, MicroBlaze ..) using just one set of hardware.Emulator examples: FS-UAE Amiga Emulator, SNES9X (games) and Bosch, QEMU (OS).Virtualization - is a technique that exposes a virtual resource (such as CPU, disk, ram, nic, etc.) by virtualizing existing physical hardware. For example there are specific CPU instruction sets designed to virtualize a CPU into more vCPUs. Main difference here is for example that you’re unable to provide a virtual machine with 16 bit processor - because you physically don’t have it. 16 bit processor can be emulated on x64 Intel (AMD) CPU but cannot be virtualized. Same goes for the rest of the hardware.Sometimes emulators and hypervisors are used in combination - for example KVM/QEMU - KVM provides CPU, Memory, disk and QEMU provides peripherals such as keyboard, mouse, monitor, NIC, usb bus, etc. - that you may not even have physically connected to the PC/Server you’re using for virtualization.

Advantages of Virtual Machines
- The tools associated with a virtual machine are easier to access and simpler to work with. Docker has a more complicated tooling ecosystem, that consists of both Docker-managed and third-party tools.
- As mentioned earlier, once you have a virtual machine up and running, you can start a Docker instance within that VM, and run containers within the VM (which is the predominant method of running containers at present). This way, containers and virtual machines are not mutually exclusive and can co-exist alongside each other.
Advantages of Docker Containers
- Docker containers are process-isolated and don’t require a hardware hypervisor. This means Docker containers are much smaller and require far fewer resources than a VM.
- Docker is fast. Very fast. While a VM can take an at least a few minutes to boot and be dev-ready, it takes anywhere from a few milliseconds to (at most) a few seconds to start up a Docker container from a container image.
- Containers can be shared across multiple team members, bringing much-needed portability across the development pipeline. This reduces ‘works on my machine’ errors that plague DevOps teams.

References
https://bitbucket.org/product/version-control-software?_ga=2.69514832.1596276106.1550568066-1848139582.1549521913
https://blog.eduonix.com/software-development/learn-three-types-version-control-systems/
https://pedrorijo.com/blog/git-init/
https://git-scm.com/book/en/v1/Getting-Started-Git-Basics
https://www.globaldots.com/advantages-of-content-delivery-network/
https://www.wpexplorer.com/free-cdn-services-for-wordpress/
https://documentation.commvault.com/commvault/v11_adminconsole/article?p=86630.htm
https://www.geeksforgeeks.org/computer-network-types-server-virtualization/
https://www.quora.com/What-are-the-differences-between-an-emulator-and-a-virtual-machine



